常见算法
本文共 11549 字,大约阅读时间需要 38 分钟。
常用排序算法的时间复杂度和空间复杂度
| 排序法 | 最差时间分析 | 平均时间复杂度 | 稳定度 | 空间复杂度 |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 快速排序 | O(n2) | O(n∗log2n) | 不稳定 | O(log2n) ~ O(n) |
| 选择排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 归并排序 | O(nlog(n)) | O(nlog(n)) | 看情况 | O(n) |
| 插入排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 堆排序 | O(n∗log2n) | O(n∗log2n) | 不稳定 | O(1) |
| 希尔排序 | 0 | | 不稳定 | O(1) |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | 稳定 | O(n+r) |
1.冒泡排序
冒泡排序(Bubble Sort)是先从数组第一个元素开始,依次比较相邻两个数,若前者比后者大,就将两者交换位置,然后比较下一对,不断扫描数组,知道完成排序。

package com.czl.Algorithm;public class BubbleSort { static void bubble_sort(int[] unsorted){ int count = 0;//使用count计数,循环次数 //外层循环,数组下标从0开始,length-1 for (int i = 0; i < unsorted.length-1; i++){ //内层循环,实现两两比较,把较大的放在前面 for (int j = 0; j < unsorted.length-1-i; j++){ if (unsorted[j] > unsorted[j+1]){ int temp = unsorted[j]; unsorted[j] = unsorted[j+1]; unsorted[j+1] = temp; } count++; } } System.out.println(count); } public static void main(String[] args){ int[] x={ 49,38,65,97,76,13,27,49,78,34,12,64,5,4,62, 99,98,54,56,17,18,23,34,15,35,25,53,51}; bubble_sort(x); for (int i = 0; i < x.length; i++) { System.out.print(x[i]+" "); } }} 2.快速排序
快速排序是随机挑选一个元素,对数组进行分割,以将所有比它小的元素排在前面,比它大的元素排在后面。具体分割操作见下面代码 。
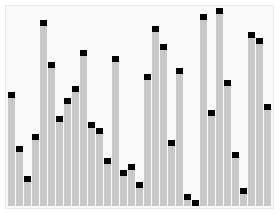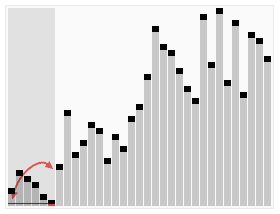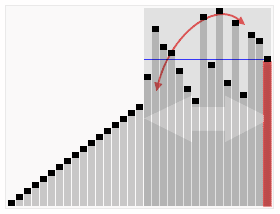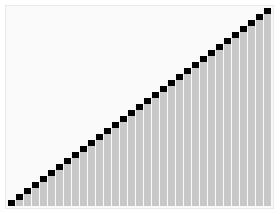 算法步骤: 1 从数列中挑出一个元素,称为 “基准”(pivot)。 2 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。 3 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。 递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
算法步骤: 1 从数列中挑出一个元素,称为 “基准”(pivot)。 2 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。 3 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。 递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。 package com.czl.Algorithm;public class QuickSort { static void quickSort(int[] arr,int left,int right){ int index = partition(arr, left, right); if (left < index - 1) { //排序左半部分 quickSort(arr, left, index - 1); } if (index < right) { //排序右半部分 quickSort(arr, index, right); } } static int partition(int[] arr,int left,int right){ int pivot = arr[(left + right)/2];//找到一个基准点 while (left <= right) { //找到左边中应被放到右边的元素 while(arr[left] < pivot){ left++; } //找到右边中应被放到左边的元素 while (arr[right] > pivot) { right--; } //交换元素,同时调整左右索引值 if (left <= right) { //交换元素 int temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; left++; right--; } } return left; } public static void main(String[] args) { int[] x = { 49,38,65,97,76,13,27,49,78,34,12,64,5,4, 62,99,98,54,56,17,18,23,34,15,35,25,53,51}; quickSort(x, 0, x.length-1); for (int i = 0; i < x.length; i++) { System.out.print(x[i]+" "); } }} 3.选择排序
选择排序(Slection Sort),简单而低效,线性逐一扫描数组元素,从而找到最小的元素,将它移到首位,如此循环操作,直到完成排序。
package com.czl.Algorithm;public class SlectionSort { public static void selectSort(int[]a){ int minIndex=0; int temp=0; if((a==null)||(a.length==0)){ return; } for(int i=0;i 4.归并排序
归并排序是将数组分成两半,这两半分别排序后,再归并在一起。排序某一半时,继续沿用同样的算法,最终,归并两个只含一个元素的数组。这个算法的重点是归并。
 算法步骤: 1. 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列 2. 设定两个指针,最初位置分别为两个已经排序序列的起始位置 3. 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置 4. 重复步骤3直到某一指针达到序列尾 5. 将另一序列剩下的所有元素直接复制到合并序列尾
算法步骤: 1. 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列 2. 设定两个指针,最初位置分别为两个已经排序序列的起始位置 3. 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置 4. 重复步骤3直到某一指针达到序列尾 5. 将另一序列剩下的所有元素直接复制到合并序列尾 package com.czl.Algorithm;import java.util.Arrays;public class MergeSort { static void mergesort(int[] arr,int low,int high){ if (low < high) { int middle = (low + high)/2; mergesort(arr, low, middle);//排序左半部分 mergesort(arr, middle + 1, high);//排序右半部分 merge(arr, low, middle, high);//归并 } } static void merge(int[] arr,int low,int middle,int high){ int[] temp = new int[arr.length]; //将数组左右两半拷贝到temp数组中去 for (int i = low; i <= high; i++) { temp[i] = arr[i]; } int tempLeft = low; int tempRight = middle + 1; int current = low; /* * 迭代访问temp数组。比较左右两半的元素, * 并将比较小的元素复制到原来的数组中。 */ while (tempLeft <= middle && tempRight <= high) { if (temp[tempLeft] < temp[tempRight]) { arr[current++] = temp[tempLeft++]; }else { //如果右边的元素小于左边的元素 arr[current++] = temp[tempRight++]; } } /* * 将数组左半部分剩余元素复制到目标数组中 */ int remaining = middle - tempLeft; for (int i = 0; i <= remaining; i++) { arr[current + i] = temp[tempLeft + i]; } } public static void main(String[] args) { int[] x={ 49,38,65,97,76,13,27,49,78,34,12,64,5,4}; MergeSort.mergesort(x, 0, x.length-1); System.out.println(Arrays.toString(x)); }} 5.直接插入排序
插入排序的基本思想是:每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。

package com.czl.Algorithm;public class InsertSort { public static void insertSort(int[] list) { // 打印第一个元素 System.out.format("i = %d:\t", 0); printPart(list, 0, 0); // 第1个数肯定是有序的,从第2个数开始遍历,依次插入有序序列 for (int i = 1; i < list.length; i++) { int j = 0; int temp = list[i]; // 取出第i个数,和前i-1个数比较后,插入合适位置 // 因为前i-1个数都是从小到大的有序序列,所以只要当前比较的数(list[j])比temp大,就把这个数后移一位 for (j = i - 1; j >= 0 && temp < list[j]; j--) { list[j + 1] = list[j]; } list[j + 1] = temp; System.out.format("i = %d:\t", i); printPart(list, 0, i); } } // 打印序列 public static void printPart(int[] list, int begin, int end) { for (int i = 0; i < begin; i++) { System.out.print("\t"); } for (int i = begin; i <= end; i++) { System.out.print(list[i] + "\t"); } System.out.println(); } public static void main(String[] args) { int[] x={ 49,38,65,97,76,13,27,49,78,34,12,64, 5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51}; InsertSort.insertSort(x); for (int i = 0; i < x.length; i++) { System.out.print(x[i] + " "); } }} 6.堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序的平均时间复杂度为Ο(nlogn) 。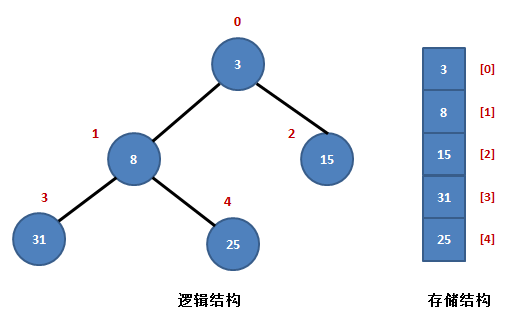 算法步骤: 创建一个堆H[0..n-1] 把堆首(最大值)和堆尾互换 3. 把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置 4. 重复步骤2,直到堆的尺寸为1
算法步骤: 创建一个堆H[0..n-1] 把堆首(最大值)和堆尾互换 3. 把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置 4. 重复步骤2,直到堆的尺寸为1 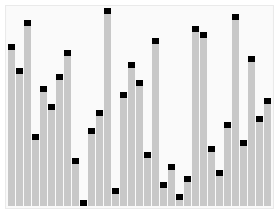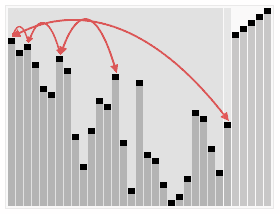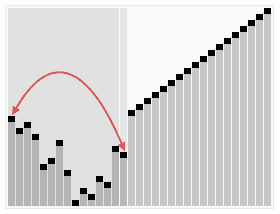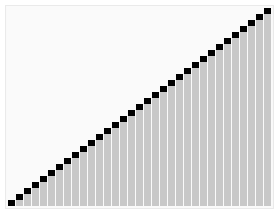
package com.czl.Algorithm;public class HeapSort { private static int[] sort = { 49,38,65,97,76,13,27,49,78,34,12, 64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51}; public static void main(String[] args) { buildMaxHeapify(sort); heapSort(sort); print(sort); } private static void buildMaxHeapify(int[] data) { // 没有子节点的才需要创建最大堆,从最后一个的父节点开始 int startIndex = getParentIndex(data.length - 1); // 从尾端开始创建最大堆,每次都是正确的堆 for (int i = startIndex; i >= 0; i--) { maxHeapify(data, data.length, i); } } /** * 创建最大堆 * @param data * @param heapSize 需要创建最大堆的大小,一般在sort的时候用到,因为最多值放在末尾,末尾就不再归入最大堆了 * @param index 当前需要创建最大堆的位置 */ private static void maxHeapify(int[] data, int heapSize, int index) { // 当前点与左右子节点比较 int left = getChildLeftIndex(index); int right = getChildRightIndex(index); int largest = index; if (left < heapSize && data[index] < data[left]) { largest = left; } if (right < heapSize && data[largest] < data[right]) { largest = right; } // 得到最大值后可能需要交换,如果交换了,其子节点可能就不是最大堆了,需要重新调整 if (largest != index) { int temp = data[index]; data[index] = data[largest]; data[largest] = temp; maxHeapify(data, heapSize, largest); } } /* * 排序,最大值放在末尾,data虽然是最大堆,在排序后就成了递增的 */ private static void heapSort(int[] data) { // 末尾与头交换,交换后调整最大堆 for (int i = data.length - 1; i > 0; i--) { int temp = data[0]; data[0] = data[i]; data[i] = temp; maxHeapify(data, i, 0); } } /* * 父节点位置 */ private static int getParentIndex(int current) { return (current - 1) >> 1; } /* * 左子节点position注意括号,加法优先级更高 */ private static int getChildLeftIndex(int current) { return (current << 1) + 1; } /* * 右子节点position */ private static int getChildRightIndex(int current) { return (current << 1) + 2; } private static void print(int[] data) { int pre = -2; for (int i = 0; i < data.length; i++) { if (pre < (int) getLog(i + 1)) { pre = (int) getLog(i + 1); System.out.println(); } System.out.print(data[i] + "|"); } } /* * 以2为底的对数 */ private static double getLog(double param) { return Math.log(param) / Math.log(2); }} 7.希尔排序
希尔排序,先取一个小于 n 的整数
希尔排序参考:,查看原文,请点击。
package com.czl.Algorithm;public class ShellSort { public void shellSort(int[] list) { int gap = list.length / 2; while (1 <= gap) { // 把距离为 gap 的元素编为一个组,扫描所有组 for (int i = gap; i < list.length; i++) { int j = 0; int temp = list[i]; // 对距离为 gap 的元素组进行排序 for (j = i - gap; j >= 0 && temp < list[j]; j = j - gap) { list[j + gap] = list[j]; } list[j + gap] = temp; } System.out.format("gap = %d:\t", gap); printAll(list); gap = gap / 2; // 减小增量 } } // 打印完整序列 public void printAll(int[] list) { for (int value : list) { System.out.print(value + "\t"); } System.out.println(); } public static void main(String[] args) { int[] array = { 9, 1, 2, 5, 7, 4, 8, 6, 3, 5}; // 调用希尔排序方法 ShellSort shell = new ShellSort(); System.out.print("排序前:\t\t"); shell.printAll(array); shell.shellSort(array); System.out.print("排序后:\t\t"); shell.printAll(array); }} 8.基数排序|执行时间: o(kn) (k为数字的位数,n为元素的个数)
基数排序是个整数排序算法,充分利用整数的位数有限这一事实。使用基数排序,需要迭代访问数字的每一位,按各个位数对这些数字分组。
比如,有一组整数,按各位为1分在同一组,再按十位分组,如此反复执行同样的过程,逐级按更高位进行排序,直到最后整个数组变成有序数组。package com.czl.Algorithm;public class RadixSort { public static void sort(int[] number, int d) { // d表示最大的数有多少位 int k = 0; int n = 1; int m = 1; // 控制键值排序依据在哪一位 int[][] temp = new int[10][number.length]; // 数组的第一维表示可能的余数0-9 int[] order = new int[10]; // 数组orderp[i]用来表示该位是i的数的个数 while (m <= d) { for (int i = 0; i < number.length; i++) { int lsd = ((number[i] / n) % 10); temp[lsd][order[lsd]] = number[i]; order[lsd]++; } for (int i = 0; i < 10; i++) { if (order[i] != 0) for (int j = 0; j < order[i]; j++) { number[k] = temp[i][j]; k++; } order[i] = 0; } n *= 10; k = 0; m++; } } public static void main(String[] args) { int[] data = { 49,38,65,97,76,56,17,18,23,34,15,35,25,53,51}; RadixSort.sort(data, 3); for (int i = 0; i < data.length; i++) { System.out.print(data[i] + " "); } }}
你可能感兴趣的文章
《软件过程管理》 第六章 软件过程的项目管理
查看>>
《软件过程管理》 第九章 软件过程的评估和改进
查看>>
《软件过程管理》 第八章 软件过程集成管理
查看>>
分治法 动态规划法 贪心法 回溯法 小结
查看>>
《软件体系结构》 练习题
查看>>
《数据库系统概论》 第一章 绪论
查看>>
《数据库系统概论》 第二章 关系数据库
查看>>
《数据库系统概论》 第三章 关系数据库标准语言SQL
查看>>
SQL语句(二)查询语句
查看>>
SQL语句(六) 自主存取控制
查看>>
《计算机网络》第五章 运输层 ——TCP和UDP 可靠传输原理 TCP流量控制 拥塞控制 连接管理
查看>>
堆排序完整版,含注释
查看>>
二叉树深度优先遍历和广度优先遍历
查看>>
生产者消费者模型,循环队列实现
查看>>
PostgreSQL代码分析,查询优化部分,process_duplicate_ors
查看>>
PostgreSQL代码分析,查询优化部分,canonicalize_qual
查看>>
PostgreSQL代码分析,查询优化部分,pull_ands()和pull_ors()
查看>>
ORACLE权限管理调研笔记
查看>>
移进规约冲突一例
查看>>
IA32时钟周期的一些内容
查看>>